Figures indexed for academic preview only. Copyright © original authors.
Copyright / UnknownLENS: Multi-level Evaluation of Multimodal Reasoning with Large Language Models
Ruilin Yao, Bo Zhang, Jirui Huang, Xinwei Long, Yifang Zhang, Tianyu Zou, Yufei Wu, Shichao Su, Yifan Xu, Wenxi Zeng, Zhaoyu Yang, Guoyou Li, Shilan Zhang, Zichan Li, Yaxiong Chen, Shengwu Xiong, Peng Xu, Jiajun Zhang, Bowen Zhou, David Clifton, Luc Van Gool
Abstract
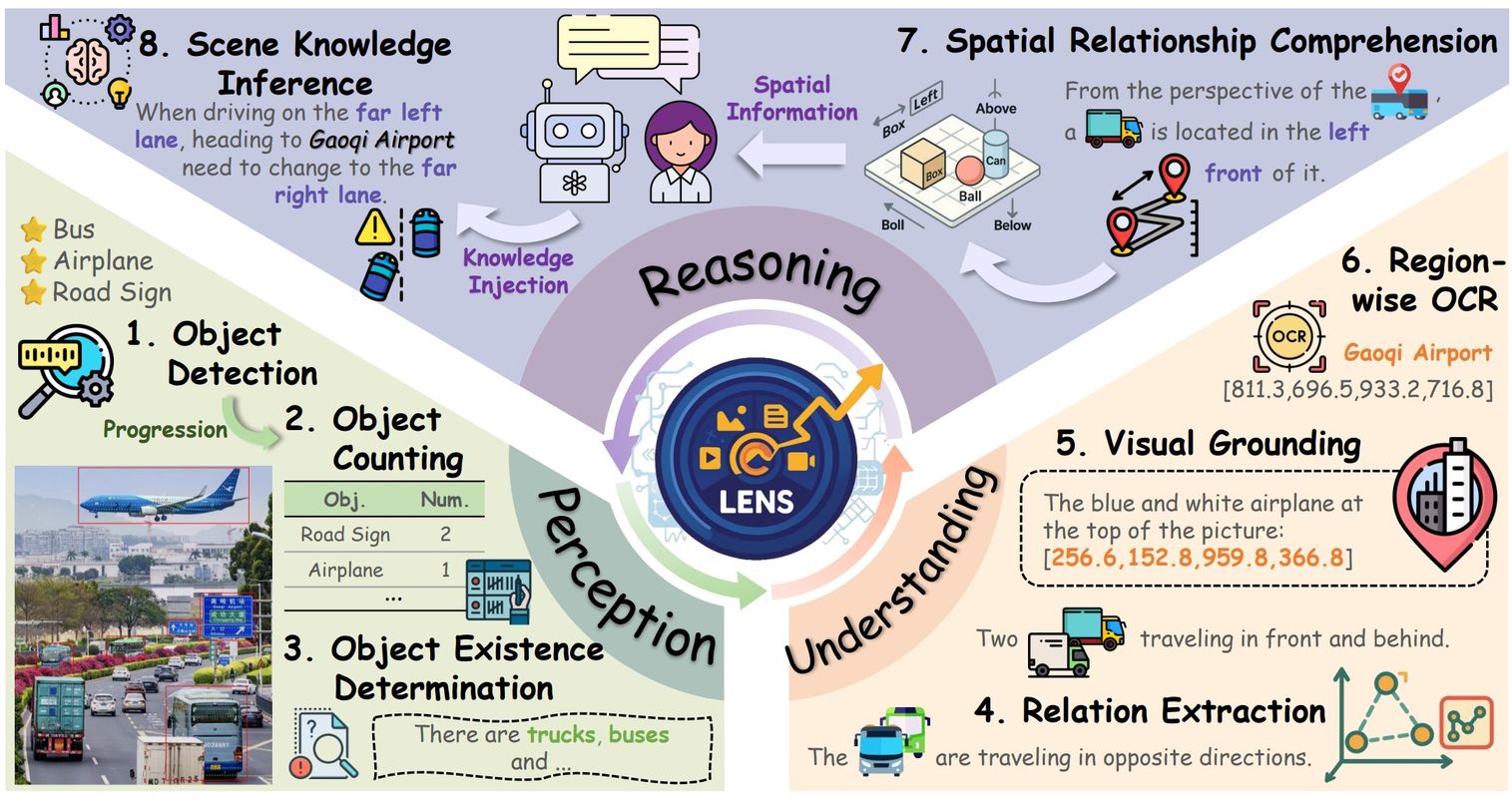
Multimodal Large Language Models (MLLMs) have achieved significant advances in integrating visual and linguistic information, yet their ability to reason about complex and real-world scenarios remains limited. The existing benchmarks are usually constructed in the task-oriented manner without guarantee that different task samples come from the same data distribution, thus they often fall short in evaluating the synergistic effects of lower-level perceptual capabilities on higher-order reasoning. To lift this limitation, we contribute Lens, a multi-level benchmark with 3.4K contemporary images and 60K+ human-authored questions covering eight tasks and 12 daily scenarios, forming three progressive task tiers, i.e., perception, understanding, and reasoning. One feature is that each image is equipped with rich annotations for all tasks. Thus, this dataset intrinsically supports to evaluate MLLMs to handle image-invariable prompts, from basic perception to compositional reasoning. In addition, our images are manully collected from the social media, in which 53% were published later than Jan. 2025. We evaluate 15+ frontier MLLMs such as Qwen2.5-VL-72B, InternVL3-78B, GPT-4o and two reasoning models QVQ-72B-preview and Kimi-VL. These models are released later than Dec. 2024, and none of them achieve an accuracy greater than 60% in the reasoning tasks.